A cím nem teljesen helyes, valójában nem az a kérdés, hogy használjunk e DTO-t, hanem az, hogy az Entity-ket használjuk e, vagy külön DTO osztályt készítsünk.
DTO-ra szerintem mindenképp szükség van, így leírom, hogy mi is az. DTO = Data Transfer Object, vagyis adatszállító objektum (Szokták még ValueObject-nek is nevezni, mert általában csak adattagjai és getter-setter párosai vannak.). A DTO lényege, hogy egy adott üzleti entitás adatait foglalja egy egységbe, mert így egyrészt az entitás adatai egyben kezelhetők, másrészt jelentős erőforrást takaríthatunk meg. Ha nem használnánk DTO-t, akkor minden adatot külön-külön lekérdezhetővé kellene tenni, ami rengeteg függvény megírását jelenti, ráadásul mivel ezeket a kliens (GUI) rétegbe is le kell juttatni, ezért minden lekérés külön hálózati forgalmat generál.
Vegyünk egy egyszerű példát:
Van egy magánszemély ügyfelünk, akiről kb. a következőket tartjuk számon: Egyedi azonosító, Név, Cím, Telefonszám. Ez egy DTO-ba foglalva – a DTO attribútumai pontosan a fent felsorolt változók - rétegenként egyetlen függvényt jelent, míg külön-külön kezelve ez rétegenként négy és nagyon oda kell figyelni, hogy ne keveredjenek a változók. Arról ne is beszéljünk, hogy ez a kliens és a szerver között – a hálózaton - is négy hívást jelent, vagyis jelentős a hálózati overhead.
A vicces az, hogy a kliens oldal szempontjából is jobb a DTO, mert ha pl. egy Gridben (JTable) akarjuk az adatokat megjeleníteni, akkor úgyis be kell tenni egy objektumba egy sor adatát.
A JavaEE szabvány úgy nyilatkozik, hogy mivel az Entity osztályok is POJO-k ezért használhatók DTO-ként is – nem azt írja, hogy ezeket használd. Nem véletlenül. Minden rendszer alapja az adat, amivel a rendszer dolgozik. Az adatokat egy üzleti rendszernél üzleti entitásokba fogjuk össze, ahol a tényleges adat az entitás egy-egy tulajdonsága. Ezeket az entitásokat adatbázis entitásokká alakítjuk és így mentjük őket az adatbázisba, hogy később, ha szükség van rájuk, elő tudjuk venni őket.
Itt jön a lényeg – egy kisebb rendszernél még meg lehet csinálni, hogy az üzleti entitásaink és az adatbázis entitásaink ugyanazok legyenek, de egy nagy rendszernél ezt nem szabad elkövetni – márpedig ahogy a neve is mutatja Java Enterprise Edition-nel dolgozunk, vagyis nem kisebb rendszert fejlesztünk. Azért nem szabad ezt elkövetni, mert egyrészt így nagyon sok lesz a redundáns adat, másrészt az üzleti entitások felépítése nem megfelelő, hogy az adatbázis szerver teljesítményét megfelelően kihasználjuk.
Nézzünk egy példát:
A rendszerünkben nyilvántartunk dolgozókat és magánszemély ügyfeleket. Ezek, mint üzleti entitások a következőképpen néznek ki kb.:
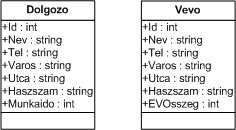
Ugyebár a két entitás csak egy tulajdonságban tér el, a dolgozónál nyilvántartjuk a napi munkaidő hosszát, a vevőnél szeretnénk látni az eddig vásárolt összeget. Üzleti szempontból ezt így érdemes elválasztani, hiszen így jól látható minden tulajdonsága az adott entitásnak és jól el is különül. Ez adatbázis oldalon kb. így néz ki:
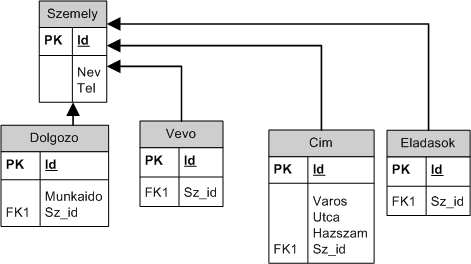
Jól látható, hogy nagy különbség van a kettő között. Elvileg az Entity-ket annotációkkal fel lehet készíteni, hogy több táblából vegyék az adatot – megmondom őszintén még soha nem próbáltam -, de ez egyrészt komoly munka, ami nem egy kezdőt igényel másrészt nem hiszem, hogy aggregált adatokat is össze lehet így rakni, mint az EVOszeg tulajdonság. Itt már jön is a külön DTO első előnye, hogy egy Entity kollekció -> DTO mapper függvényt egy junior fejlesztővel is meg lehet íratni, hiszen egy doksiban megmondjuk neki, hogy így kell kinéznie a DTO-nak, ez a fő Entity, neki csak az a feladata, hogy megkeresse az Entity-hez kapcsolódó többi Entity között azt, amiből a megfelelő tulajdonság kinyerhető, az Entity-k pedig generáltathatók. A másik megoldásnál viszont egy senior kell, aki jól ismeri az EJB3 szabványt, gyorsan meg tudja csinálni a feladatot. SZVSZ ez a megoldás átláthatatlanabb is.
Megtehetnénk azt is, hogy a generált Entity-jeinket mozgatjuk a rétegek között, de ezzel több komoly baj is van.
1. Felesleges adatok is mennek – nem biztos, hogy az Entity összes tulajdonságát használni is fogjuk.
2. Biztosítanunk kell, hogy a kliens minden szükséges adatot megkapjon, vagyis mivel lusta betöltést érdemes használni, kell írnunk olyan eljárásokat, amik az összes szükséges csatolt Entity-t is betöltik, hogy a kliens olvasni tudja azokat.
3. Mivel a jelenleg nem csatolt állapotú EJB-k visszacsatolásánál elvesznek a kapcsolatok, aniket nem töltöttünk be, ezért a mentésnél úgyis meg kell írnunk az áttöltő eljárást.
4. Nem tudjuk megoldani a jogosultsághoz rendelt adatmegjelenítést. Mi van, ha az a kérés, hogy csak az arra jogosult személyek láthassák a személyek címeit. Ha Entity-t használunk, akkor mentésnél nagyon oda kell figyelni, hogy mi megy be.
5. Olyan információt adunk át a GUI-nak, ami rá nem tartozik. A GUI-nak nincs köze az adatbázisunk felépítéséhez, pedig így ez az információ is átkerül oda!
Programozási szempontból is jobb a DTO, ugyanis ha a kliensen adatrácsba akarjuk tenni az adatokat, úgyis át kell fejtenünk őket egy objektumba soronként, mert a JTable ezt képes használni. Ráadásul ha akarunk írni általános eljárásokat, amik többféle DTO-t is fel tudnak dolgozni, akkor kell egy közös ősosztály, ahol van egy azonosító tulajdonság, az Entity-k generálva viszont POJO-k még nem találtam olyan Entity generátort, aminél meg lehetne adni egy ősosztályt. (Természetesen ott van a reflection mint lehetőség, de ez nem biztos, hiszen csak futási időben derül ki, hogy a keresett tulajdonsága létezik e a vizsgált objektumnak, egyébként is nagyon lassú. )
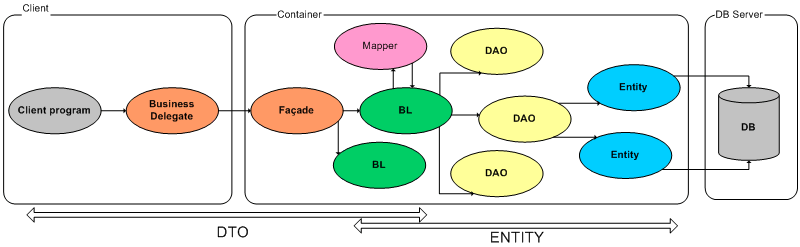
Az első részben az ábrán jelöltem, hogy a BL réteg az, ahol az Entity-DTO átalakítás megtörténik a rendszerben. Ezt érdemes betartani, mert a rétegeink így válnak el egymástól teljesen, hiszen a BL feletti rétegekre már nem tartozik olyan információ, ami az adatok tárolásával függ össze, illetve a BL alatti rétegeknek már nincs köze az üzleti információkhoz. Ezt lejjebb nem lehet helyezni, mert a DTO egy üzleti entitás, vagyis az adatelérési rétegnek nincs elegendő információja egy ilyen előállításához. (Egy DTO feltöltéséhez több DAO meghívása is szükséges lehet, így azt egyik DAO objektum sem tudja előállítani.) Egyetlen esetben azért ez a szabály is áthágható, ha a DTO-t arra használjuk, hogy a benne levő adatokkal szűrjük a legyűjtendő Entitásokat, akkor érdemes átadni a DAO-nak, hogy ne kelljen egy irgalmatlan sok bementi paraméterrel rendelkező függvényt írni :-).
Még ehhez a témához tartozik a Mapper osztály, aminek a feladata a DTO-Entity adatáttöltés. Ezt az áttöltést bele lehetne írni magába a DTO-ba is, így csökkentve a kezelendő osztályok számát. Amiért érdemes külön osztályba szervezni ezt az az, hogy ha külön osztályban van a mapper kód, akkor csökken a kliens mérete. Ugyanis ha a DTO-ban van, akkor a DTO hivatkozásokat tartalmaz az Entity-kre, vagyis ahhoz, hogy a kliens működjön, a kliensnek ismerni kell az Entity-ket, különben nem tudja használni a DTO-kat. Ha viszont ezek külön osztályban kapnak helyet, akkor a kliensnek a szerver osztályai közül csak a Facade-et és a DTO-kat kell ismerni a működéshez, vagyis egy Ant scripttel pillanatok alatt lehet csinálni egy olyan JAR fájlt, ami csak ezeket tartalmazza (hiszen ezek egyike sem hivatkozik más osztályokra.)
Ez akkor lehet fontos, ha a kliens programot Java Web Starttal juttatjuk a kliens gépre, hiszen így egy új verzió esetén jóval kisebb a letöltendő fájlok mérete. (És az sem elhanyagolható szerintem, hogy a kliens megint csak olyan osztályokat birtokol, amiben nincs felesleges – esetleg veszélyes – információ a rendszer felépítéséről.